Only to understand: the DBKit relies on Sqlite?
Too little too late. I asked for the “Easy Database Connectivity” a loooong time ago.
The idea was simple. Have a controller object and inputs assigned to the controller. Then the controller takes care of the db events for add, change, delete.
I wrote my own, but I really wanted it baked into xojo for actual RAD. I thought it’d also help FileMaker devs get interested in Xojo.
![]()
No. They wouldn’t have to, I suppose, if Xojo were in usage by enough people to justify one of the open source ORMs doing a Xojo binding or version.
Microsoft didn’t have to provide an ORM for their own products (said open source products work with .NET) but they did (Entity Framework) and it’s okay as such things go.
I don’t have a lot of love for ORMs anyway due to the impedance mismatch between objects and relational data and the black box emitting sometimes problematic SQL … SQL DB query optimizers can be temperamental enough just on their own. I use straight ADO.NET and “think in SQL” when I write software that talks to a DB.
I can understand as you have very old database habits of DBase and FoxPro.
ORMs make it easier for a less talented developer to build queries to access data as per ones need.
Looks like they’ve made it work with SQLITE, MySQL, PostgreSQL and ODBC
At least there seems to be code for that
thats usually the disconnect
when you want objects for dealing with individual rows / objects its fine
but then you have a need for raw queries
and most forms didnt/dont have a way to do that as well
so you have this munged environment where some stuff uses the form and some doesnt
And Sql Server, pre-Entity Framework. I did look at Hibernate / NHibernate and of course EF when it came out … it just didn’t really save me time for my problem domain at least, vs a thin wrapper over ADO.NET (GetDataReader, GetScalar, ExecuteNonQuery, plus parameter helpers). If I did more CRUD work it might have been a different calculus, but I’m building software to pump data in and out of a DB in bulk, and fast. Millions of records in per month, dozens of complex queries per second out.
You are right, though, part of it is my ancientness. When Fox added inline SQL to the language syntax, it took me awhile to accept that a SQL query optimizer could be as good or better than my hand-tuned DML calls. I crossed that Rubicon in probably 1998 or so though.
They do, and they don’t. It spares them knowing SQL or different SQL dialects, or having to translate between their object model and the DB. But at the same time, to really understand how to write good ORM calls or lamda expressions or whatever (and to trouble shoot the occasional performance hiccup), you have to understand what SQL it generates and why what it generates is (un)desirable and therefore how you ought to structure your ORM calls to produce good SQL … ORMs paper over the “impedance mismatch” between set-oriented SQL and object-oriented clients with varying degrees of success and you’ll never understand the weak points of a particular ORM abstraction and intuit best practices unless you understand everything you have to understand anyway to just do standard pass-thru (and hand-tuned) SQL.
Then there’s the issue of debugging. If I have a perf problem I’d rather deal with SQL written by a human than cryptic SQL generated by an ORM. EF has gotten better in this regard but it’s still a bit of a slog figuring out how it’s talking to the DB.
In a lot of organizations the use of stored procs is mandated anyway. Not that I agree with that across the board, or that ORMs can’t cope with sprocs, but … it’s reality.
I think that a lot of the mediocre / slow DB access in apps today is down to uninformed use of ORMs. To me it just adds cognitive load, ultimately (and, often as not, technical debt), without adding all that much value. I can and have used them when I’ve been in environments that mandated them. Admittedly, EF + C# makes some aspects of parallelized DB access simpler – again probably more up front than ultimately. And I just prefer the cleanness of rolling your own SQL.
It’s not really about talent. It’s about RAD and not doing busy work for simple interfaces. Plus, you’d have to supply the SQL to the controller.
Being in the middle of writing my first Webserver, your remarks get my full attention.
I concur with @HalGumbert that using ORMs make writing code easier and faster.
There may however be situations in which ORMs may not produce the desired/best result but I still have to encounter them.
Vapor/Fluent (which I use) is open source and written by professional coders.
For the time being, I am faster using Fluent and if need arises I could use the .custom case to roll my own queries ![]()
Spot on. It’s not about having to use a controller ALL the time. More like when you need it.
Thinking about FileMaker, there’s the current record, like a Contact record, which could use one controller for the List of Contacts and another controller for the Selected Contact. Then to show phone numbers, addresses, invoices would use three more controllers.
Each would have its own SQL statement. The Contact List might have “select * from Contacts” or a where appended to filter the list. If a contact was clicked in the list a List Controller event would fire to pass an ID to the Selected Contact controller to call “select * from Contacts where ContactId = ?”.
Then the Selected Contact controller would fire an event to then tell the related table controllers to selected their records.
So you’d still need to code sql statements, but not bother having to manually set each control…
I dunno what the DBKit does though…
What I can’t understand is why they didn’t made a universal DB connector API available which could make it possible to provide multiple database interfaces. Others have it (like Java with JDBC) and can connect to nearly every DB System.
That’s industrial standard. Now they come up with the next own Solution which isn’t working really. Should not be but …
Ouch! Has a bug…
DBKit is still in beta but is quite functional.
‘…still in beta but is quite functional’ - another eternal beta.
A database connector brought to you by courtesy of the documentation department ![]()
From documentation:
The included control subclasses, while nearly identical, are not cross-project compatible because their super classes are specific to the project type.
The API2 x-plat dead end is looming and the documentation tries to talk away this severe design limitation.
As concision: writing with Xojo a Desktop Application as XPLAT I will suffer from not available and available but not performant Database Connectors. As Spaceport for this I get a Database Manager which isn’t running proper on top.
I don’t want to complain but I am used to have a big set of real performant Database Connectors (JDBC) which are all running like hell and of a good Database Manager which is working correct in my IDE (IntelliJ->Datagrip and / or Netbeans Services->Database).
So the only argument for Xojo is now which one? (and no, I will not mention the language but I can see it is the better way instead of using Xojo).
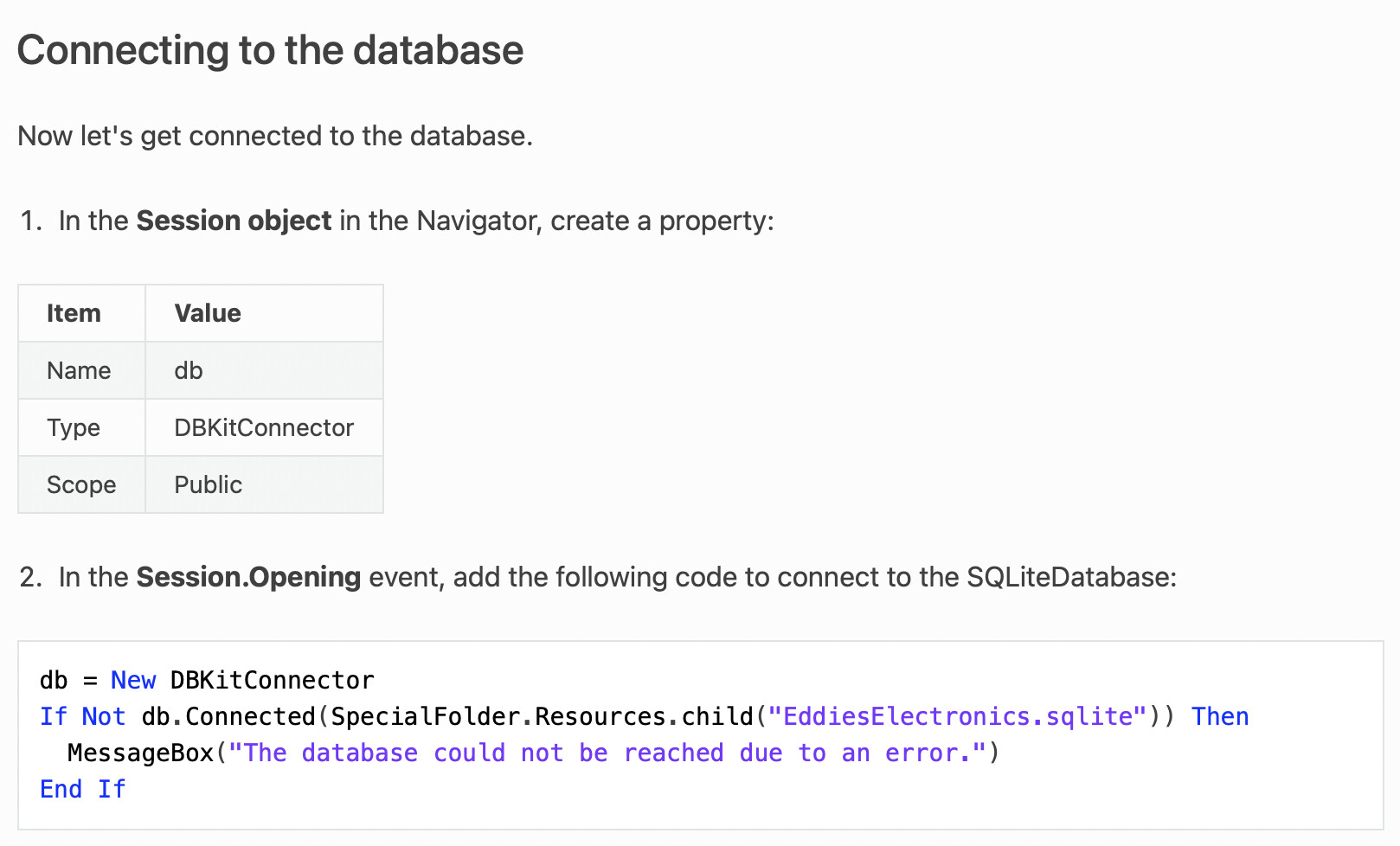
Genius chose …
Let’s wait for the Android version of the tool …
So frustrating. I didn’t see any posts about getting feedback about what DBKit should do. Just more “I know better” it seems,
Makes me glad I dropped Xojo.
A lot of the conversation about it has been in the testers channels which are hidden from view
I have the code but haven’t really looked at it intently
Its downloadable as part of their examples - which are "online only - in the IDE
And awesome pain in the ass when you’re on an airplane like I’ve been a lot this year
Docs are the same way