SOMEONE please post this to TOF
He’s done at least 2 things wrong
- used CHR but …
- is trying to put the BYTES in not the Unicode code point
me.Text = "¶" + " " + &uB6
OR
Me.Text = "¶" + " " + Encodings.UTF8.Chr(&hB6)
SOMEONE please post this to TOF
He’s done at least 2 things wrong
me.Text = "¶" + " " + &uB6
OR
Me.Text = "¶" + " " + Encodings.UTF8.Chr(&hB6)
This is what they consider their official support channel. Their users get the support they get because of the choices Xojo has made.
Xojo’s Unicode support is a mess.
Certainly things like FORMAT and other built in functions have issues with non-English locales
Those I’d consider bugs
What other things have you run into ?
isn’t UTF-8’s purpose to solve challenges with so many global locales? ![]()
Granted, people who never had to work with non-US locales don’t care (any yes, I know that you are working with international customers too, I’m pointing to the green master of disaster). So, as always, if you are targeted audience for those bugs, you don’t really care if it might work for some ![]()
But it is probably easier to get rid of international special characters than hoping that the Greens will care.
UTF-8 does in many ways
But there are functions people try to use IN Xojo & its frameworks that do things wrong
As if they are coded to only assume USA or English conventions
Dates, times, currency and other locale specific things seem to be many of the culprits
And that is separate & apart from UTF-8
I’m sure if someone cared tot hey could find recent discussion of this on TOF but … myeh
https://tracker.xojo.com/xojoinc/xojo/-/issues/72471
https://tracker.xojo.com/xojoinc/xojo/-/issues/66499
yes, you are speaking to someone who has suffered greatly from this ignorance.
There are some problems even more hurting. Math. Currencies. And many more. So I guess Coding is not the biggest one. Setting all to UTF8 is like an insurance not to get stresses. Many people don’t get how important that is and run into issues which are not even related to Xojo by self but to the used encoding.
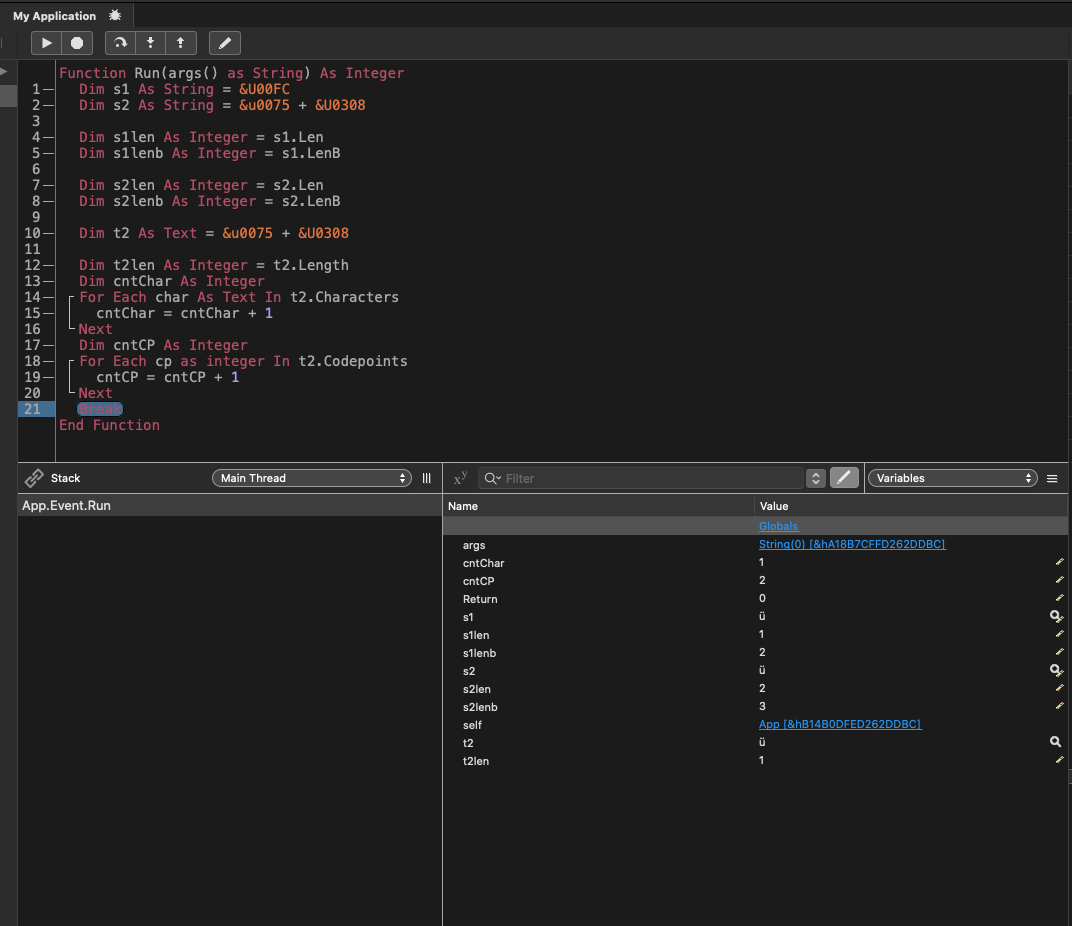
Can’t find the thread in TOF anymore. It had to do with string.length which delivered different results for ‘u’ and ‘ü’. I do remember that the sample code for the workaround in doc was faulty. It was a ‘we are transitioning from API1 to API2’ issue.
.NET returns 1 for “ü”.Length (as it should). It is 1 character long. That it involves 2, 3 or 4 bytes for that particular character is an implementation detail depending on what encoding you’re using.
There is a separate method to get the byte count, as there should be (Encoding.GetByteCount()).
If Xojo is returning some value other than 1 for the length of any one character string regardless of encoding, then that is a bug, a confused API design, or both. Which is certainly reminiscent of other hacks they are known to do, such as parsing the OS version string instead of calling OS APIs, with resulting abstraction leakage for users not on their “happy path”.
I don’t have experience with .NET but I understand there are 2 ways to show ü:
Xojo has problems with the second one, reporting it as Length 2 with 3 bytes.
ah yes - text fixed this since it didnt count “bytes”, or code points, but “characters”
All of the APIs on the Text type operate in characters. For example, if the APIs worked in terms of Unicode code points, it would be possible to corrupt data using Left/Mid/Right if the positions happened to be in the middle of a composed character or grapheme cluster. Working in characters also avoids situations where the length of ‘é’ can be either 1 or 2.
Text got this right
But … ![]()
In an act of unfathomable wisdom, Xojo decided that Text is deprecated, leaving people who need to deal with text and not with stringy bytes alone. This was the first moment when I thought that Xojo won’t become my tool…
The inability to deal with Text alone excludes Xojo from the low code tools list.
“His ways are not our ways; his ways are past finding out …”
Be nice if they just kept both
BUT, in this case, they listened to customers who bitched long & loud about how hard it was to use text, how slow it was for using as a generic bucket of bytes ( ![]() ) and other complaints
) and other complaints
So they deprecated text ![]()
I’d prefer they keep both since TEXT has characteristics that make it perfect for dealing with TEXT
but … ![]()
I will never understand people complaining about something new because they don’t like it, just don’t use it. But that’s the issue with Xojo and deprecating old stuff. You have to complain about new approaches, as otherwise the old ones will be sunset ![]()
Yes but - ITS NEW IT MUST BE BETTER !!! right ???
Text was “better” for the things it was designed for - representing TEXT
Was it better for manipulating long ranges of bytes ?
NO … but why not ?
It was designed for representing TEXT - not BYTES !
but … ![]()
This was part of the Xojo framework - which was 100% OPTIONAL (except for iOS)
No one shoved it down anyones throat
But OMG Its new we should adopt every last piece of it yesterday !
![]()
I remember those discussions, and never understood them. The idea of frameworks was as wise move and finally something promising and a modern approach of doing things. I believe it would have avoided tons of current challenges, but ok … I am just silly and others know better.
That’s the funny thing. The average Xojo user is happy, that it is not called BASIC any longer, but many seem to adhere to BASIC concepts.
I wish they had kept Text as well. Speed issues they could have fixed over time I believe. However, Strings still have the same flaws it always did. So nothing fixed, nothing to see. Move on.