<html>
<head></head>
<body>
<script type="text/javascript">
function jsTest() {
let startTime = new Date().getTime();
let myTestString = "1230,345,456,6780,789,901,1240,346,457,5680,679,345,4560,678,789,9010,124,346,4570,568,679,";
for (let i = 0; i <= 10000000; i++) {
let sTagsArray = myTestString.split(",");
let kk = sTagsArray.length;
for (let j = 0; j < kk; j++) {
let sNewString = sTagsArray[j];
}
}
let endTime = new Date().getTime();
console.log((endTime - startTime) / 1000);
}
jsTest();
</script>
</body>
</html>
Have I got that right?
< 8.5 seconds in Firefox running on a feeble mini PC with an Intel Atom processor.
So we’re taking a comma-delimited list of strings, turning it into a string array, and then accessing each element. But that’s a LOT of string allocations. In a real program you would probably address each element by index rather than making a copy of it, particularly if you’d only use it once inside the loop. So IMO this test is including a lot of pointless string allocation pressure. But maybe that’s on purpose, IDK.
My point being that depending on how Swift memory management works the real world performance of this kind of thing could likely be sped up quite a bit.
If they’re comparing VB6, they’re probably running on WIntel. In general WIntel is faster than Apple Silicon, just nowhere near as efficient. Does anyone remember the days when Apple’s chips were inefficient and the switch to Intel was considered beneficial
To make it a fair comparison run the test with Xojo on your Mac.
It probably was, until Xojo recently fixed a massive performance degradation.
Out of curiosity, I ran the equivalent through Delphi on a Mac M2, running Windows 10 Arm inside Parallels. I suspect Delphi’s TStringList object carries a fair overhead.
35s - Not remarkable in either direction, really, but …
These are kind of a bad tests as heavily optimizing compiler could optimize loops away for code like this where assigned variable is not actually used and the end result is the same after each iteration.
The code could easily be optimised, both by the coder and the compiler.
The OP just wanted a like-for-like stress test.
It’s like saying ‘Hey, you 4 guys - cut my lawn with scissors’
Letting one of them use a lawnmower when the others aren’t watching, doesn’t tell you anything about how fast they use scissors, but yeah, it would get the real world job done faster.
Sure… I caveat this with ‘Opened Delphi for the first time in 25 years, about a week ago…’
procedure TForm1.Button1Click(Sender: TObject);
begin
var MyTestString , OneField: String ;
var x,i: integer;
var OutPutList:TStringlist;
var f: string;
MyTestString:= '1230,345,456,6780,789,901,1240,346,457,5680,679,345,4560,678,789,9010,124,346,4570,568,679,' ;
OutPutList := TStringList.Create;
OutPutList.Delimiter:= ',';
OutPutList.StrictDelimiter := True;
//start timing here
try
for x:=0 to 10000000 do
begin
OutPutList.Clear;
OutPutList.DelimitedText:= myTestString; //unsure if this is needed to match original
for i := 0 to OutPutList.count-1 do
begin
OneField:= OutPutList.Strings[i];
end;
end;
finally
OutPutList.Free;
end;
//get timing here
end;
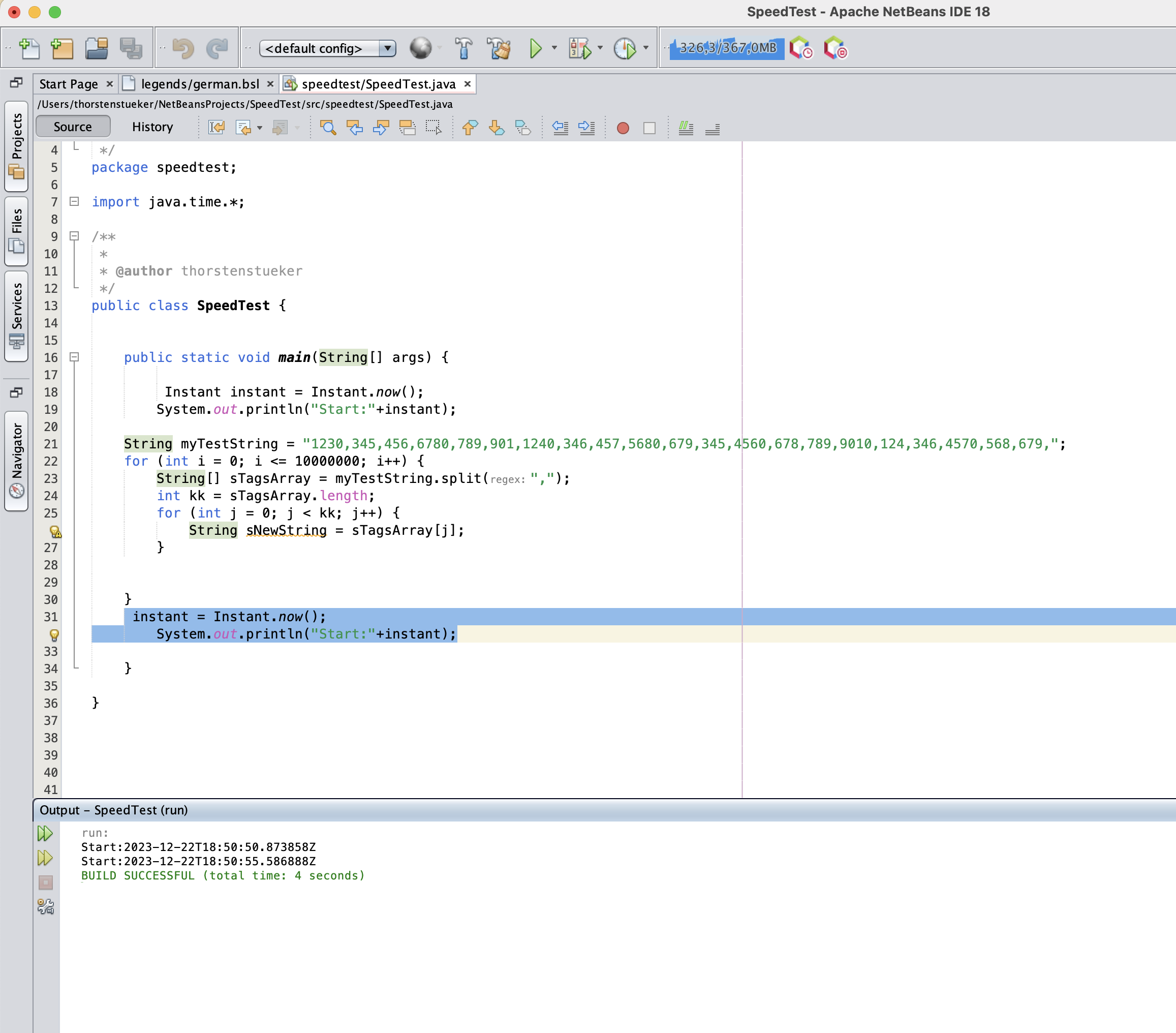
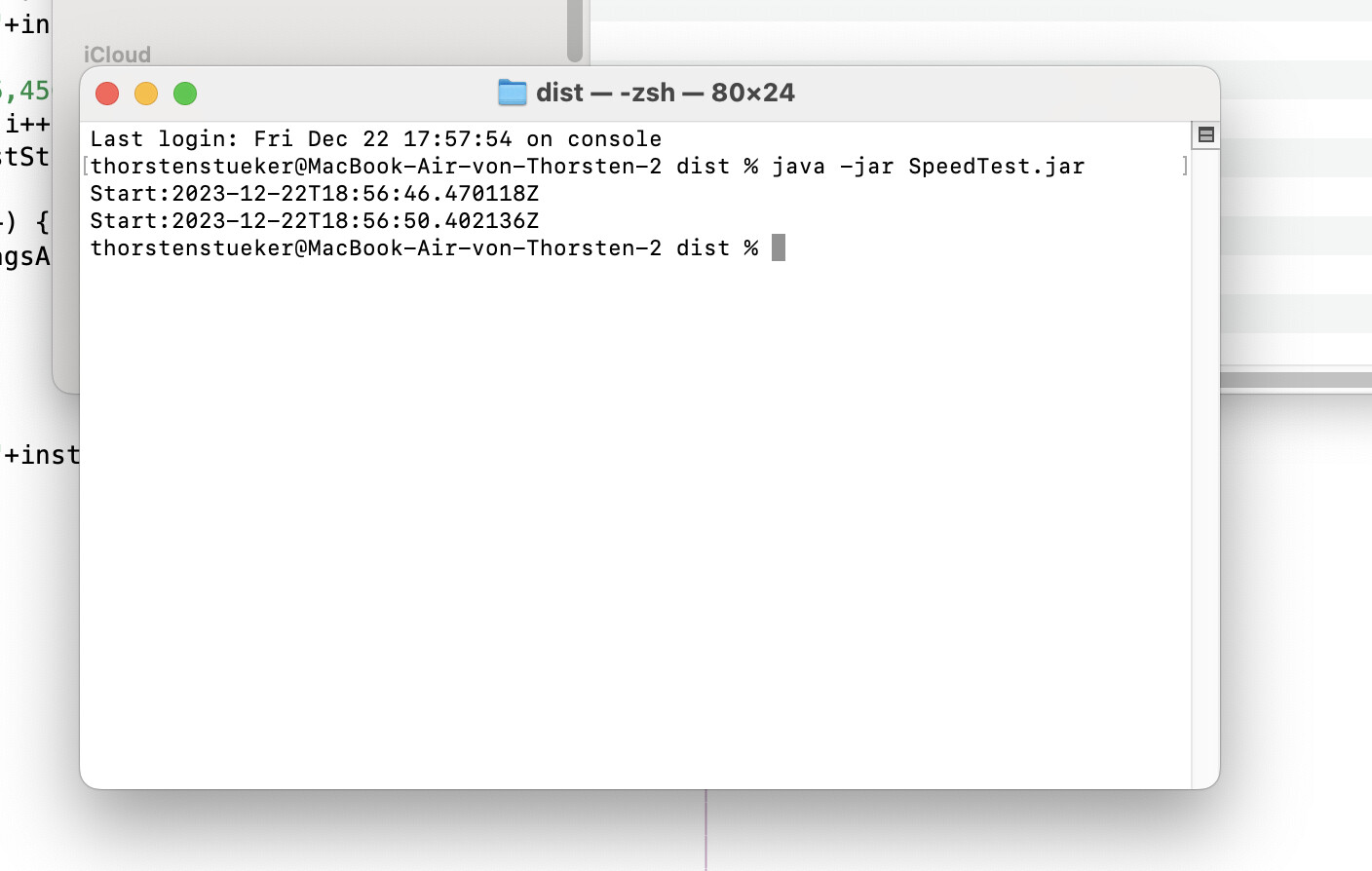
Cause the exucution time is sooo long I tried on a MacbookAir 15". The execution time showed on the first picture is the execution time in Debil mode in Netbeans IDE. The second one shows the execution time started in JVM directly. OS: MACOS. Tested also but too lacy to write: Windows. Not slower.
So Iran say Java does that Job within 4 until 5 seconds.
Running it builded with CN1 on IOS it runs 17 seconds and on Android 33 seconds. Only for information.
And there is no ugly syntax and no verbosity. I have no idea how people are speaking about that and in the same moment they start to discuss Xcode, C# and Swift. The Syntax is very close to Java and let me say it so: the others are not less verbose. I can’t understand the Idea behind the bashing of a language. Which is fast, reliable und nice.
Less than five seconds for Java seems almost too fast. Are you sure Java does not optimize loops away or move something out of the loops? If that happens, it’s not benchmarking the same as compiler or interpreter that does not optimize code at all.