The homepage states that steampipe unifies query of data APIs by providing a layer that allows making queries in SQL that does the translation to an API-specific request.
Does anyone know steampipe or has experience of working with it?
I don’t have any experience with it, but I don’t quite get the point either.
Querying an api is quite easy, in the simplest form you get a JSON back, which you can easily save away with a modern postgres version (in MongoDB style), for example, and then you do your SQL there as usual. The solution seems to specialize on AWS, Azure, Google Cloud etc., but not on all APIs in the world. That’s okay too, but that’s probably more likely to be the clientele who don’t need such a solution.
I’m still missing something. Sometimes I’m jealous of not being a genius. Life would be so much easier.
I think the point here is the abstraction of APIs. Individual APIs are handled by plugins. It is a typical low code approach. While working with APIs is easy for trained developers, low coders struggle frequently with it. Low code tool vendors offer products that abstract the API handling, thus reducing the effort the developer has to make. These products come with unreasonable price tags.
I posted it here to collect feedback from trained developers how this would (reasonably) fit into their tool chain.
Addendum: sometimes the low code platform itself poses a problem when dealing with APIs because functions can have faults in their implementation, i.e. JSON handling functions. And as all comes prefabricated, there is no way out other than waiting for the vendor fixing it or, if possible, using a plugin.
See it so. Xojo has low code approaches. Like inherit instance is standard for new window. That is not always the best choice. Working for example with Java Swing there is no such approach. You have to code that entire part by hand. On the other side you have the control how it is behaving, how it is inheriting and so on.
That control Xojo takes away from the users. The same with threads. There is a problem with glitches when using threads. Therefore Xojo does not want to use it
Ah thanks, understood, I didn’t have “low code” or Xojo on the screen. JSON (even with Xojo plugins) is just unnecessarily complicated (if you compare it to GO, Java, probably even any other programming language). Unfortunately I can’t help with this topic, I either process the APIs directly or save the data in a DB.
Don’t think app development, think data wrangling. I use it sporadically - it’s great for data analysis, BI etc. Lots of plugins for lots of data sources. Very efficient. Also using SQL seems somehow to solve the problem of missing API end points. I mostly use the csv plugin which allows you to use SQL to query single or multiple csv files. Install on Mac and Linux are a snap, Windows not so much.
Hm. I have a LOT of text files to process – a mix of CSVs, occasionally other delimiters like pipes or tabs, and now and again a fixed-width file. I have been using the desktop / JET / Access drivers for this in the past via MDAC for this, but that’s now deprecated and I believe one has to use the ODBC driver built into Windows 10+. You would still use a schema.ini to define the file schema.
I will have to look into this though because it seems like it would be a cleaner way to read such files. A key issue is whether it can handle these different formats I mentioned, though. I already have a CSV reader of my own design (can use any delimiter, not just commas, defaults to reading everything as strings but you can apply types to columns) which I could expand to handle fixed-width, so that’s in the mix too. I don’t generally need to query so much as just bulk load, but querying could be nice at times (e.g., skip certain junk records I’m not interested in).
ETA: Maybe not my first choice in a Windows environment. By the time you install Windows subsystem for Linux and then Ubuntu, that’s a lot of overhead, and then you don’t have .NET bindings as far as I can see so everything has to be done via the (Ubuntu) command line. I need to automate this without so many dependencies and layers of cruft.
That said, it could be a useful interactive tool at times, especially if it can do UNIONs.
I would use HSQL DB for it and open the Files I need to open with the JDBC connectors and the import filters I have for Java. Okay, CSV I would not handle with them cause it is simple to handle directly. And that’s it. Q quarter of an hour of work runs on all platforms immediately.
First Name|Surname
Eric|Idle
Graham|Chapman
John|Cleese
Michael|Palin
Terry|Gilliam
Terry|Jones
and how to process it …
import csv
csv.register_dialect('pipes', delimiter='|')
# using csv.reader
with open('myfile.csv', newline='', encoding='utf-8') as f:
r = csv.reader(f, 'pipes')
for line in r:
# each line is a Python list of strings
print(line[0], line[1])
# using csv.DictReader where the first row contains headers
with open('myfile.csv', newline='', encoding='utf-8') as f:
r = csv.DictReader(f, dialect='pipes')
for line in r:
# each line is a Python dictionary
print(line['First Name'], line['Surname'])
for fixed length strings you could use Python’s string slicing …
I use Steampipe more for answering that ad-hoc questions or for exploring new data files with unfamiliar schemas before I do something more permanent with them. You could definitely integrate it with your dev stack.
I use Powershell heavily for checking the integrity of data, error detection, file comparison, data changelogs, fraud detection, data cleansing, transformation and reporting - occasionally publishing results to Excel adding graphs etc.
Powershell is cross platform (win, mac, linux), has deep libraries for including Microsoft office integration (not all of which are cross platform - however the cross platform support continues to strengthen).
(Don’t laugh) I even have a Xojo Web app that calls Powershell scripts to process uploads on a Linux web server.
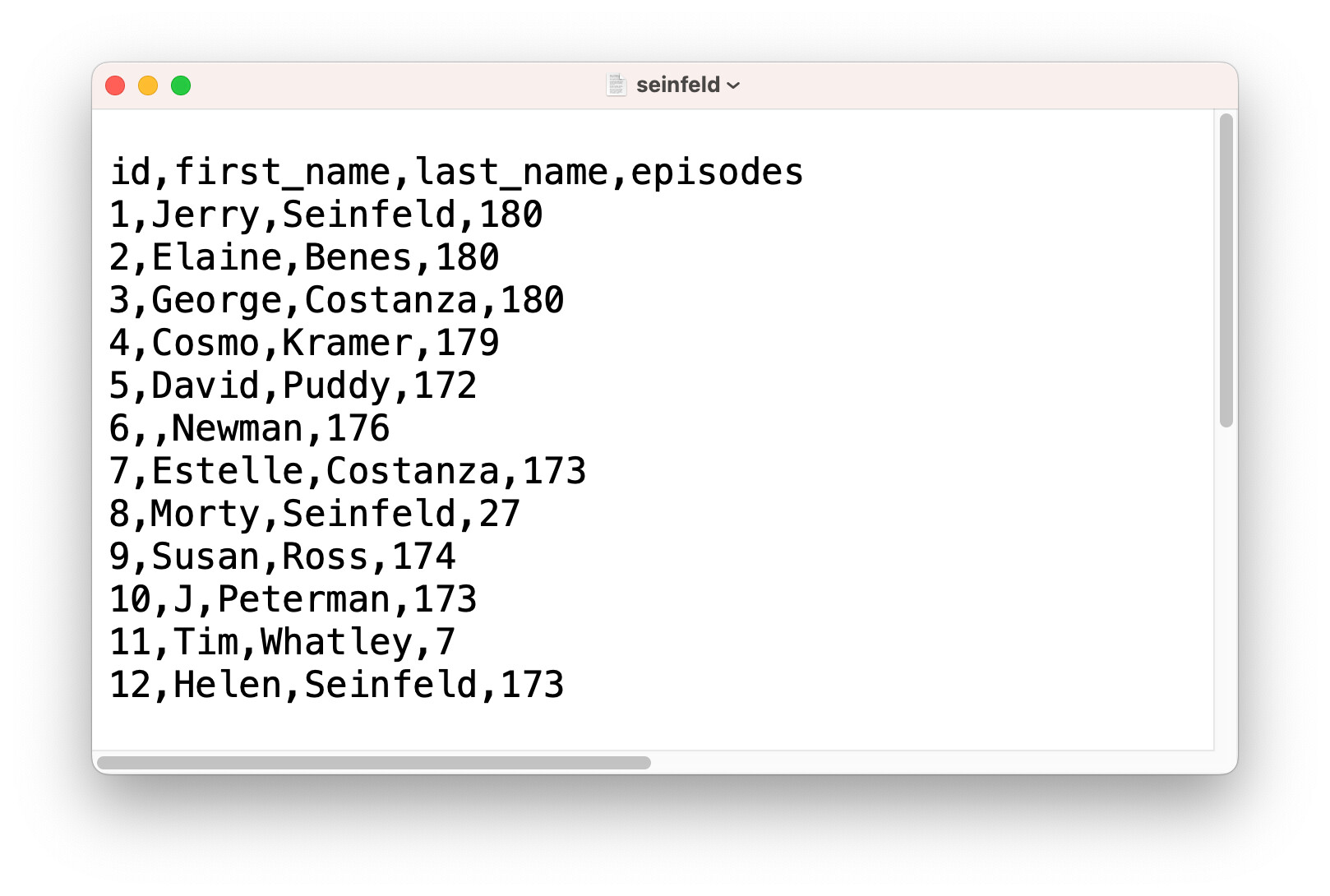
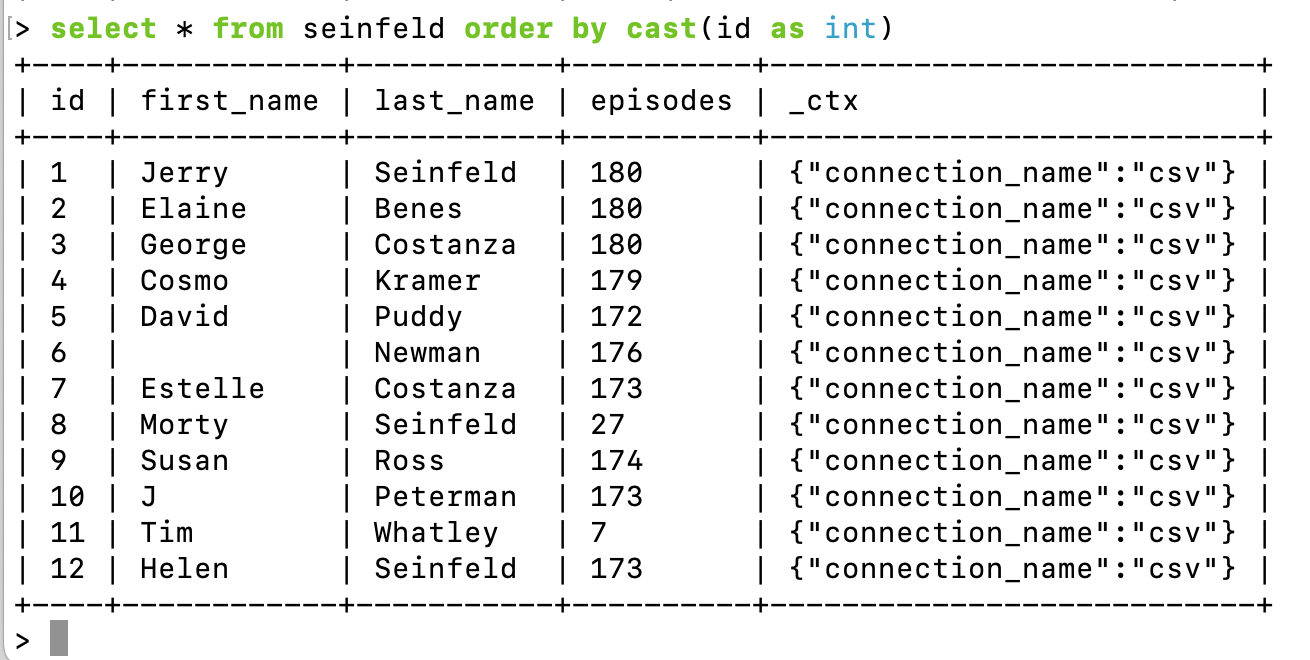
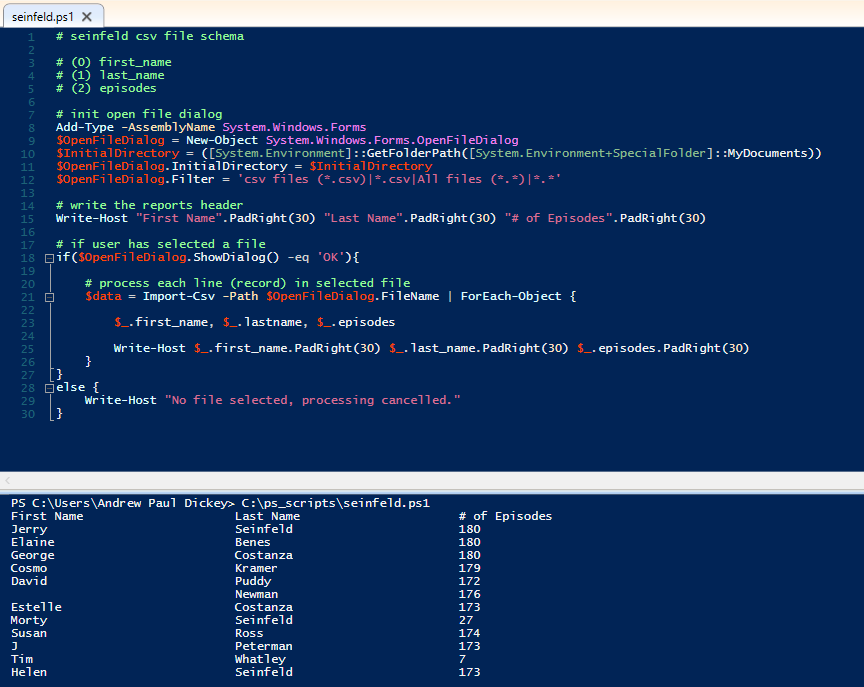
To complete the loop, here is the Seinfeld (select *) example for Powershell.
I used to have a few dozen lines of very simple Python code to read Excel files. We used Aspose for most Excel, but it could not deal with very old Excel formats like Excel 2.0 that we’d occasionally get, whereas the Python lib did. Forget the name – xlr I think?
I didn’t use it more broadly because I had to launch a shell and monitor it for completion, pick up errors from stderr, etc. It was a little clunky but worked well. This time around I’m thinking of using EPPlus since my client is already familiar with it, albeit, an older open source version and not the current commercial product.
Thanks for reminding me of the Python csv lib too.
Since I already have a reasonably battle-tested .NET CSV reader of my own design, I may just go with that and modify it to understand MDAC / ODBC schema.ini files, handle fixed width, etc. Wouldn’t be that hard to do.
Fortunately, there are lots of options for me to consider.
Mine uses an indexer to access columns in the current row and has a .ToDataTable() convenience method.
In the old system, MDAC import to a DataTable was flexible enough but I wrote it as an experiment to get a feel for whether I could get away from all that (now obsoleted) infrastructure. The main limitation was that for a fairly common use case, SELECT with a JOIN to bring together 2 text files (customer name/address and trade data joined by account #) was mighty handy. So, everything was designed around an OleDbDataReader returning the result of that JOIN. I could just as well import the 2 files to a couple of Sql Server #temp tables and join them that way, I suppose, but there are problems with that approach as well. Sql Server’s BULK INSERT is a whiny little snowflake that needs everything “just so”, for example, and it doesn’t have a mechanism to produce a table schema that matches the column heads in the actual file. It does things like upchucking on rows that have trailing spaces, needing end of line sequences specified in advance as it can’t auto-detect them, etc.