Since someone asked the question I’ll answer
Usually depth first and breadth first search apply to hierarchically organized data. This might be described as a “tree”.
Note that we dont have to actually be “searching”. We can use the traversal as a search or a way to print out the dat a in specific orders etc.
A directory hierarchy would be a great example.
In there you have directories with files and possibly other directories.
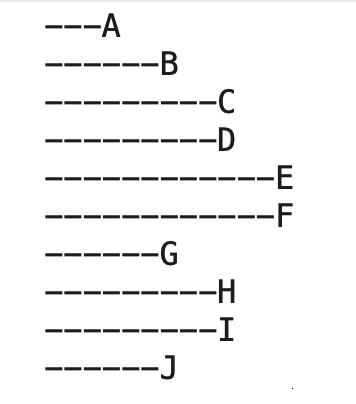
Lets assume, for this discussion, you have a tree like
a
b
c
d
e
f
g
h
i
j
a is the “top” and everything is contained by a
Thats really not a requirement but it make is easier to talk about the algorithms
In a depth first traversal you try to go down the tree as deeply as possible before you go across/so if we were to traverse our sample depth first using the following mechanism (stated in pseudo code)
ProcessNode
if node has children then
for all children ProcessNode
end if
print node value
the results would be
e
f
d
b
h
i
g
j
a
The point is the algorithm dives in as deeply as possible BEFORE doing anything with the current node, hence “depth first”
Breadth first is quite different. Breadth first process entire “layers” of the hierarchy before moving deeper into the hierarchy. As such it’s algorithm is quite different and its actually easier to write as a non-recursive algorithm (depth first can be written not recursively as well using a similar technique)
ProcessNode( node )
create a queue
add the node passed to the queue
while the queue is not empty
set thisnode to the node at the front of the queue
process thisnode
add all children of thisnode to the end of the queue
remove thisnode from the front of the queue
wend
The results of this kind of traversal are
a
b
g
j
c
d
h
i
e
f
There are other kinds of traversals as well that are suited to other kinds of data structures
Heres a sample in Xojo