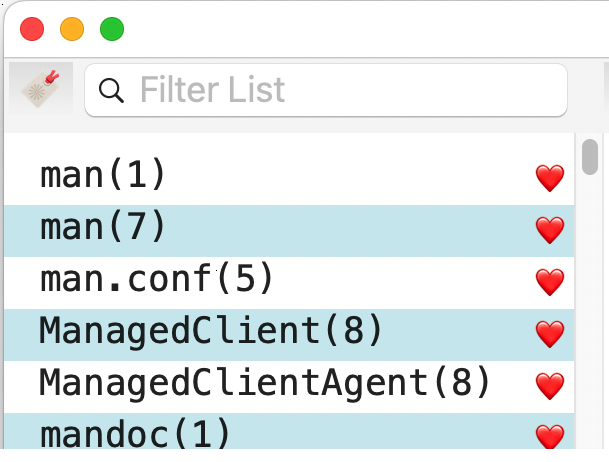
What would you expect to type to filter the list to what you might be looking for?
Note : the Table is populated with a “SELECT” statement in SQL
have the App add “%” to each end of entry and use like
require the user to enter any leading or trailing “%”
With #1… .if the user typed “man”… it would search for “%man%”
otherwise it would search for only what the user entered… and if they were not savvy enough to know a bit of SQL, they might never realize why they can’t find something.
Levenshtein distance is more useful for “fuzzy” matches rather than for filtering. Like in spell checkers. SQLite does have a spell check extension available - search for sqlite spellfix.
Personally, I would assume the user knows how to spell what he’s looking for and only wants entries that contain the exact search term. I would use two queries, the first that matches with only a trailing ‘%’, ordered by the returned item, then a second query using leading and trailing ‘%’, excluding entries already matched in the first query.
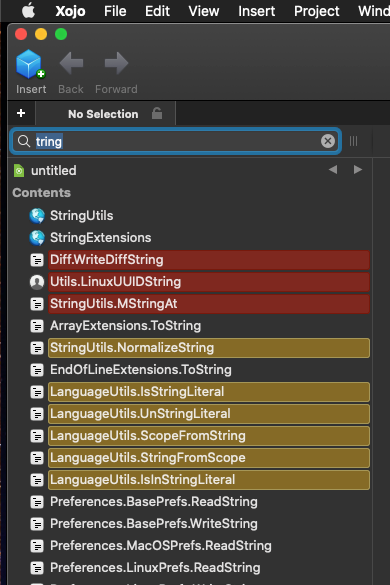
Except that’s not how they appear to me. To me, they just all have the word “string” in them, with the only difference being how long the entire item is. Again, sorting all that begin with “string” at the top, then sorting the remaining (separately) would make more sense. Then I can focus on or skip entire sections that are similar instead of having to read each and every item.
Fair
I think if you look closely you will see that items that require fewer changes to become the search string String appear closer to the top than others that require more changes
StringUtils requires removal of “Utils” - remove 5 characters at the end
StringExtensions require removing “Extensions” - removing 10 characters at the end
If it was just lexical sorting Extensions should appear before utils
But it doesnt
It is subtle but it seemed useful
Maybe this is more illustrative
if the search is for “string” then I get the same results
But titles that are more similar to tring appear closer to the top
How are the top entries “more similar”? It’s just length!
And yes, I know exactly what it was doing, and it’s why I was pointing out that unless there are entries that contain, for example, “strange” or even “ring” for it to fuzzy match to, then all it’s really doing is ordering by character length (same as “number of characters that must be removed”). In other words, this list could simply be created using “where name like ‘%tring%’ order by length(name)” without needing an LD function.
That’s why I state that LD is only good for fuzzy matches, such as when trying to find a “correct” entry for a misspelled word.
Note how your result list it the same for both searches.
And yes, IMO in this particular case, lexical sorting is actually better (but only sorting within each “group” as I laid out before).
Length is relevant because that influences how many changes are required and so alters the LD distance
I suppose the IDE’s filter could have been made to find everything that had some maximum distance and that would have been a better fuzzy match
But that also would require using a version of sqlite that had such a thing built in - which it doesnt by default - or by adding a custom sqlite function
Neither of which Xojo did/does
Not sure if SQLite supports regex but I have found in other sql languages that it’s significantly faster. In Postgres you use ~ “search” maybe SQLite supports regex searching? If someone knows.
No regexp() user function is defined by default and so use of the REGEXP operator will normally result in an error message.
The default match() function implementation raises an exception and is not really useful for anything.
so GLOB is the only one that seems to be available in all builds