I’ll run some tests. I’m pretty sure I’m correctly counting characters as I split the source code into individual characters in the Markdown parser and then calculate offsets using their index in this array.
I had been using String.Split("") although since @bkeeney’s earlier post I’ve also retrofitted iterating with String.Characters to the same effect.
I now really think StyledText must be counting bytes.
That’s going to be a real ballache. The parser only tells me the character position (as a 0-based offset) in the original source that each node (e.g. bold, italic) starts at, not the byte position. I’ve no idea how I’d go about translating between the two efficiently.
Lots of thoughts
None of them printable or likely to solve your issue
Guess my curiosity is the usage
Is the text area going to take markdown, render it as styled text which is still editable ?
Then eventually take that styled text and put it back out as markdown ?
or something else ?
went back and reread original post
not sure how you propose handling some other markdown stuff that text area doesnt represent like lists etc ?
And can I edit in the markdown AND text at the same time ?
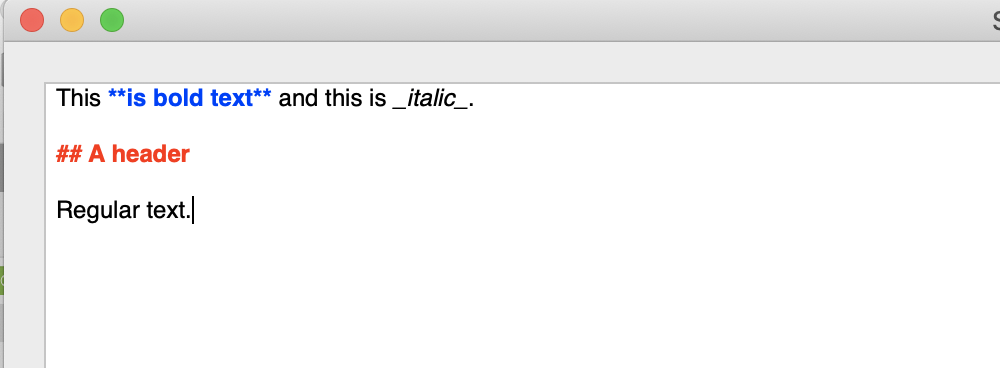
I have a TextArea subclass (MarkdownArea). It’s purpose is to allow the user to enter text as Markdown and it will style selected parts in a user-definable way. For example, it could style bold text (e.g: **hello**) in red or style ATX headers (e.g: ## A Header) in green.
The user can simply type in the MarkdownArea and it’ll colour the text as they type. It does this by periodically parsing the TextArea.Value string into an AST and then a custom AST-Walker traverses the AST and applies the custom styles for certain nodes. For example, when the custom walker gets to a “strong-emphasis” node it gets the 0-based start position in the TextArea text and the number of characters in the bold node and calls MarkdownArea.StyledText.Bold, startPost, numChars) = boldValue.
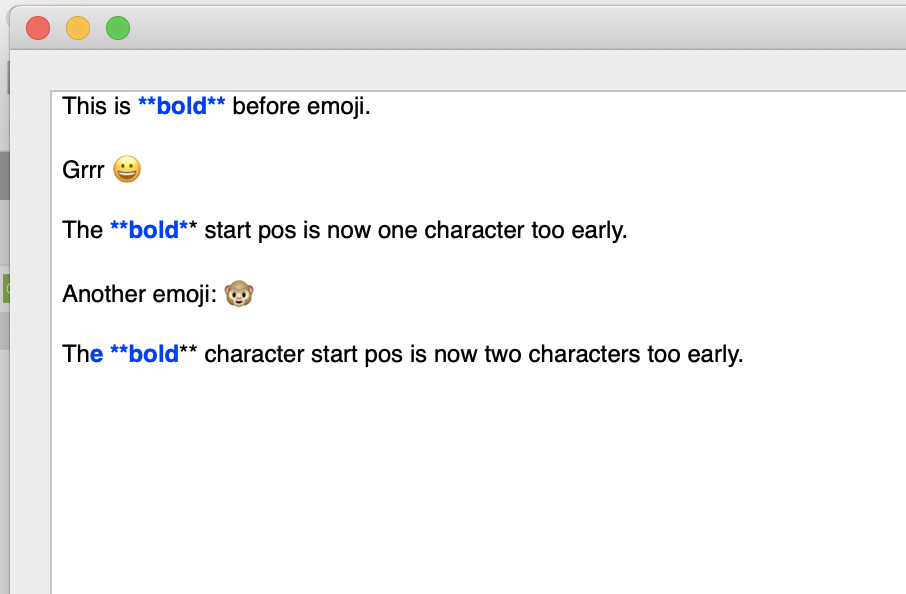
This works a treat so long as the MarkdownArea doesn’t contain emoji because when it does, I get this:
Notice that bold is highlighted fully (including the flanking **) before any emoji occurs in the text. For each emoji you insert into the text area, the offsets for all the nodes afterwards are wrong. You can see this in the screenshot because the **bold** after the first emoji doesn’t highlight it’s final * and the **bold** after the second emoji doesn’t highlight the last two *.
Can you tell me what you used to say ABCD is 4 characters and BCD is 5 characters?
Len(Length) say 4 characters for both and LenB(Bytes) say 4 bytes and 7 bytes respectively
StartPos.Value is the value of the start position TextField on the window and Length.Value is the value of the length TextField on the window. You can see in the demo video that StartPos is set to 0 and Length is set to 4.
I think @DaveS is wrong about the exact length of 😀BCD but I think he was write to spot that this is a byte issue.

 BCD is 5 characters?
BCD is 5 characters?